
A layman's approach to the world of dimensionality reduction
The world of statistical learning is central to the modern ambitions of millions of aspirants seeking to enter the exciting and lucrative world of machine intelligence. As such, supervised and unsupervised learning are the fundamental branches of machine learning. Unsupervised learning includes clustering, dimensionality reduction etc. One of the most popular unsupervised learning algorithms is PCA (Principal Component Analysis), which is used for dimensionality reduction. In simple terms, dimensionality reduction means reducing the size of the data. The compression of data should be in such a way that we do not lose out on essential information (or features), which may further be useful when other supervised learning algorithms are operating on it. The purpose of this article is to emphasize on the mathematics behind dimensionality reduction, which forms the basis for Principal Component Analysis.
Let us explore.
The need for dimensionality reduction
Machine learning algorithms (supervised or unsupervised) are known to work best if the data being fed to it has gone through an entire cycle of pre-processing. This is necessary in order to make data amenable for machine learning tasks. Machine learning algorithms fail to understand data that has not been pre-processed accordingly and thus produce poor results. One of the issues which we may encounter is the size of the data, which might be of higher "dimensions" (i.e. a set of data attributes pertaining to something of interest to a business), thus making it hard for algorithms to process it. So, it is always a good practice to reduce the dimensions in our data so that the developed model is a robust one.
Representational learning
Consider the following dataset: { [1,3],[2,6],[14,52],[0,0],[19,57],[6,18] }
The above dataset contains vectors belonging to R2 vector space . There are totally 12 numbers and we need to store all of them. As the number of vectors increase, more numbers will be required to store them (for every n data points, we will require 2*n numbers to store/represent the entire dataset). If n is large, this method of representation will prove to be costly. So a smarter way to represent the above data would be as follows:
Representation vector: {[1,3]}; Coefficients:{1,2,14,0,19,6}
On observing the original dataset, it is evident that every point is of the form [x,3*x] where x is a scalar. So all points in the dataset will fall on the line y=3*x. We have [1,3] to be a representative of this line and all the points in the original dataset can be reconstructed by multiplying the coefficients with [1,3]. The representational vector can be any point on the line y=3*x and not necessarily [1,3] in this case.
Now where is the compression? Well, if we followed our original representation then it would require “d*n” numbers to represent the entire dataset (d being the dimension of the data and n being the number of data points), whereas in the new representation, we would require ‘d+n’ numbers to represent our data (d+n is much smaller than d*n for large values of d and n).
Thus for a simple dataset as the one above, the above method of representation has proved to be effective. How this new dataset will be processed by ML algorithms, well, that is a discussion for another day.
Does the above method work for all datasets?
A point to be observed with the above representation is that using the coefficients and the representational vector, we were able to reconstruct the dataset without missing any values. This was possible because all the points were falling on a line. Now imagine we had a point in the dataset which wasn’t falling on the line y=3*x. Using the above representation, we will not be able to reconstruct the entire dataset (i.e the points not falling on y=3*x can never be retrieved). A typical real world data-distribution will never have all data points falling exactly on a line or a plane. So we need to find a way to compress this data and also ensure that we do not lose out on essential information in the compressed representation.
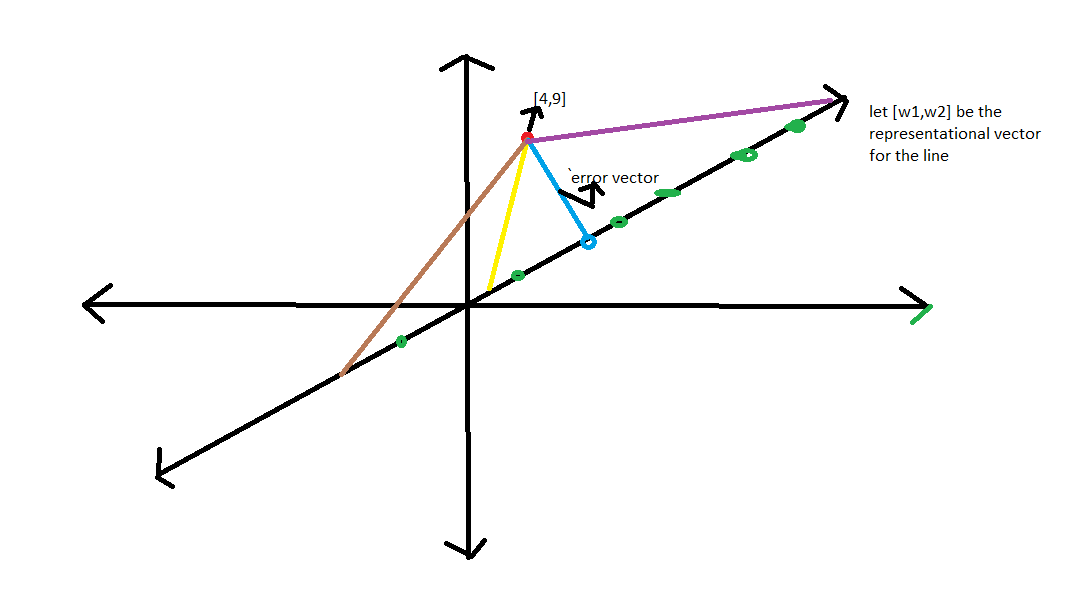
For the sake of simplicity we are considering points in lower dimensions.(i.e R2 or R3). Now assume a point [4,9] which does not belong to the line y=3*x. Since it is not possible to represent this point, we try to find a proxy for [4,9] by projecting it onto the line. While we are ready to compromise on the possibility of being able to reconstruct our data perfectly, the projection should be in such a way that we do not lose out on essential information. While this notion of error might not have a massive impact on datasets of smaller dimensions, it can prove to be a huge determining factor if we are dealing with say images for example (which are of high dimensions) . Coming back, we can project the point [4,9] onto the line in different ways as has been demonstrated in the above diagram. The brown, yellow, blue and violet lines represent the error vectors upon projection. The projected points are of the form
C*[w1,w2]
where “C” is a constant (scalar) and [w1,w2] is the vector representing the line. Thus, the goal is to solve the following optimization problem.
To minimize length(error vector)
Where [x1,x2] is the point to be projected
*Error vector=[x1-c*w1, x2-c*w2]
Upon solving the problem we get the optimal solution for “c”, which is:
c=(x1*w1+x2*w2)/(w12+w22)
While the above explanation was with the assumption that we were projecting the points on the right line, the real problem lies in finding the best line of projection. We can have any number of lines onto which we can project our points but the best line is the one which minimizes the “reconstruction error”. Another important point to note while projecting points is that we must be able to differentiate the points on the new line. So the projection needs to be in the direction of maximum variance.
It has been proved that the eigenvectors represent the direction of the maximum variance. From this fact we infer that eigenvalues represent the actual variance (magnitude). So it makes sense to project the points onto the eigenvector corresponding to the largest eigenvalue. This is an iterative procedure and we terminate the projection process until the residue/error is close to negligible. The eigenvectors are also known as principal components. The first principal component is considered to be the most important one since it holds most of the data post projection.
Thus, in this article we have tried to explore the math behind dimensionality reduction and the fundamentals required before we further explore the working of Principal Component Analysis.


